The software stack
To do any kind of machine learning at scale, you need a machine learning library that takes care of interfacing between your high level programming language (almost always Python if you are into niche/alt things Julia or if you are really into punishing yourself R (I tried…)) and low level matrix operations on CPU/GPU.
These machine learning libraries facilitates a few essential things. First, these libraries offer optimal implementations of elementary mathematical operations on data matrices/tensors on CPU or GPU(sums, min, mean, products, dot products etc. etc.). Second these libraries facilitate automatic differentiation. Most libraries have the options to store/compute a gradient (1st derivative wrt some function) value for all parameters that are to be estimated.
Estimating parameters in a model almost always boils down to moving parameters values (intelligently) such that the model does its ‘job’ better or achieves its ‘goal’. The way we define a models’ ‘goal’ is in terms of a ‘loss function’. We’re not going to go into loss functions specifically here, there are plenty resources to learn about those. The loss is generally a function of all parameters in the model. A lot of optimization (though not all) is done by gradient descent, the gradient of the parameters wrt the loss is minimized, because if all parameters have gradient 0 wrt the loss their at a (local) minimum. The brute force way of establishing the gradient for a set of parameter values (still sued in many SEM or statistical software frameworks) is to sequentially move each parameter up, then down a little step, record the change in loss. This takes 2*#-parameters evaluations of the loss function, after which all parameters move in the optimal direction and the process re-starts. A key aspect of any machine learning framework is to use automatic differentiation(Wengert 1964; Griewank 2012) to provide the partial derivatives of the loss function with respect to the individual parameters, in order to speed up optimization greatly (see autodiff on Wikipedia for a fuller explanation). the logic here is that the sign and magnitude of the derivative/gradient tells you which steps to take for optimal gradient descent, to reduce the loss. Automatic differentiation takes twice the compute as a single evaluation of the loss, regardless of the number of parameters involved.
Troughout the book callouts labeled important will highlight key concepts in ML, we don’t have separate ML chapters but the concepts are sprinkled throughout. Studying these topics until you have a conceptual grip on them will make you a better consumer/developer of biological ML models. You don’t have to immediately as they are frequently abstracted away by layers of software and convenience.
The key concepts to study further here are gradient decent and automatic differentiation, which are basically the building blocks of how all deep learning models are trained.
Arguably the four most popular libraries that provide a framework for automatic differentiation, GPU/CPU compute abstraction and reconfigure model elements (attention layers, dense layers, convolutional layers, recurrent networks etc etc) are PyTorch, JAX,tensorflow and keras. These libraries are still quite general, they are able to accommodate a vast universe of models. Build on top of these framework there are libraries like Huggingfaces’ transformers. Huggingface (HF), a company named after an emoji (🤗) and started to develop a chatbot for teens in 2016, at some point pivoted to being the backbone behind language and vision language models and maintain a few powerful libraries that form a top layer over PyTorch,TensorFlow and keras.
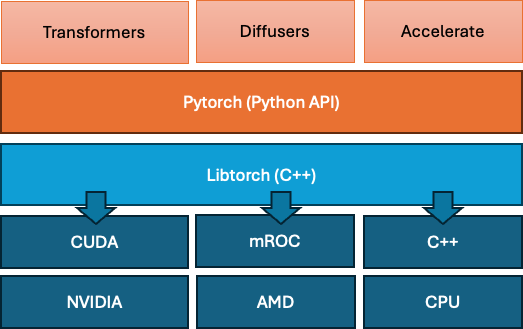
We’ll be working with transformers (and a few derivative libraries like trainer and accelerate), when we cannot us the off the shelf models we’ll implement small pieces of code in Pytorch to fit within transformers models. What transformers offers us are highly structured validated implementations of models, of training loops/code of tokenizers (we’ll get into all those). It also directly integrate with all models and dataset hosted on https://huggingface.co. Hosting on HF is free for public models and datasets, though given these can go into the terabytes one wonders how long that can last. When training a model, you can save its weights directly to their hub, from the script. This greatly reduces the friction between model training and deployment.
Under that layer pytorch is a python API that lets you interface with tensors, matrices, their gradients, the full graph of a model containing multiple matrices etc. Under the hood libtorch is the C++ library that then translates (and in some cases complies) those models and graphs into hardware specific languages (so CUDA for NVIDIA GPUs for example) where the actual computation happens. In this course we will work in pytorch directly but at no point will concern ourselves with the lower layers.